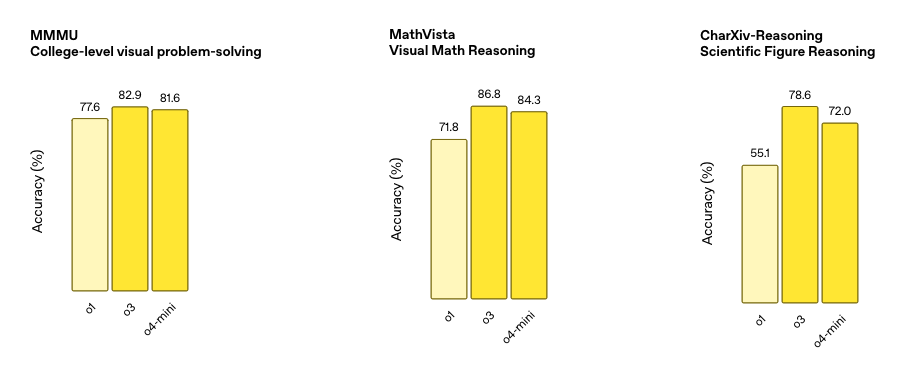
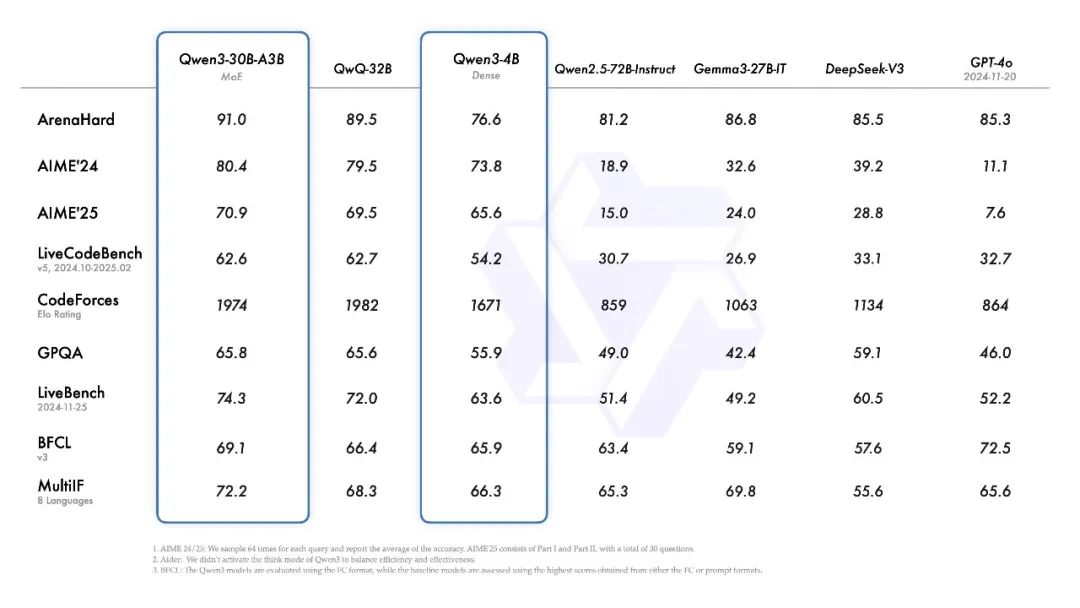
4曰29日,阿里云宣布推出 Qwen3,这是 Qwen 系列大型语言模型的最新成员。旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。

Qwen3开源了两个 MoE 模型的权重:Qwen3-235B-A22B,一个拥有 2350 多亿总参数和 220 多亿激活参数的大模型,以及Qwen3-30B-A3B,一个拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型。此外,六个 Dense 模型也已开源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,均在 Apache 2.0 许可下开源。
|
|
Layers |
|
|
|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32K |
| Qwen3-8B | 36 | 32 / 8 | No | 128K |
| Qwen3-14B | 40 | 40 / 8 | No | 128K |
|
|
64 | 64 / 8 |
|
|
|
|
Layers |
|
|
|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
经过后训练的模型,例如 Qwen3-30B-A3B,以及它们的预训练基座模型(如 Qwen3-30B-A3B-Base),现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。对于部署,推荐使用 SGLang 和 vLLM 等框架;而对于本地使用,像 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 这样的工具也非常值得推荐。这些选项确保用户可以轻松将 Qwen3 集成到他们的工作流程中,无论是用于研究、开发还是生产环境。
Qwen3 的发布和开源将极大地推动大型基础模型的研究与开发,目标是为全球的研究人员、开发者和组织赋能,帮助他们利用这些前沿模型构建创新解决方案。
核心亮点
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。如上文所述,Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
Qwen3 模型支持 119 种语言和方言。这一广泛的多语言能力为国际应用开辟了新的可能性,让全球用户都能受益于这些模型的强大功能。
预训练
在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用的数据量几乎是其两倍,达到了约 36 万亿个 token,涵盖了 119 种语言和方言。为了构建这个庞大的数据集,我们不仅从网络上收集数据,还从 PDF 文档中提取信息。我们使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 改进提取内容的质量。为了增加数学和代码数据的数量,我们利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。
预训练过程分为三个阶段。在第一阶段(S1),模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识。在第二阶段(S2),我们通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练。在最后阶段,我们使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense 基础模型的整体性能与参数更多的Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。对于 Qwen3 MoE 基础模型,它们在仅使用 10% 激活参数的情况下达到了与 Qwen2.5 Dense 基础模型相似的性能。这带来了训练和推理成本的显著节省。
后训练
开始使用Qwen3
以下是如何在不同框架中使用 Qwen3 的简单指南。首先,Qwen3提供了一个在 Hugging Face transformers 中使用 Qwen3-30B-A3B 的标准示例,要禁用思考模式,只需对参数 enable_thinking 进行如下修改,对于部署,可以使用 sglang>=0.4.6.post1 或 vllm>=0.8.4来创建一个与 OpenAI API 兼容的 API endpoint。
要禁用思考模式,您可以移除参数 –reasoning-parser(以及 –enable-reasoning)。
如果用于本地开发,您可以通过运行简单的命令 ollama run qwen3:30b-a3b 来使用 ollama 与模型进行交互。您也可以使用 LMStudio 或者 llama.cpp 以及 ktransformers 等代码库进行本地开发。
高级用法
Qwen3 提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。
Agent示例
Qwen3 在工具调用能力方面表现出色。推荐使用 Qwen-Agent 来充分发挥 Qwen3 的 Agent 能力。Qwen-Agent 内部封装了工具调用模板和工具调用解析器,大大降低了代码复杂性。
要定义可用的工具,可以使用 MCP 配置文件,使用 Qwen-Agent 内置的工具,或者自行集成其他工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。